There are 3 components to the below dashboard:
- Predictive Impact Analysis
- Prescriptive Modelling
- Recommended Budget Allocation
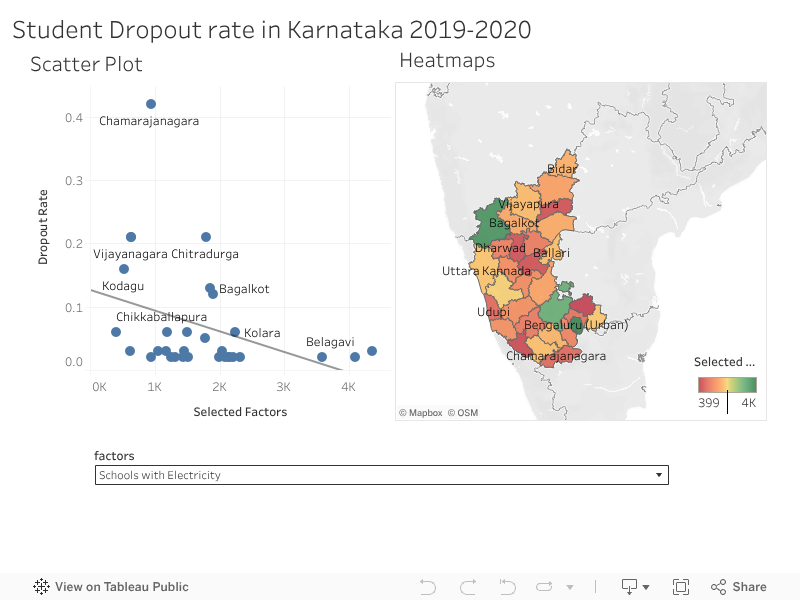
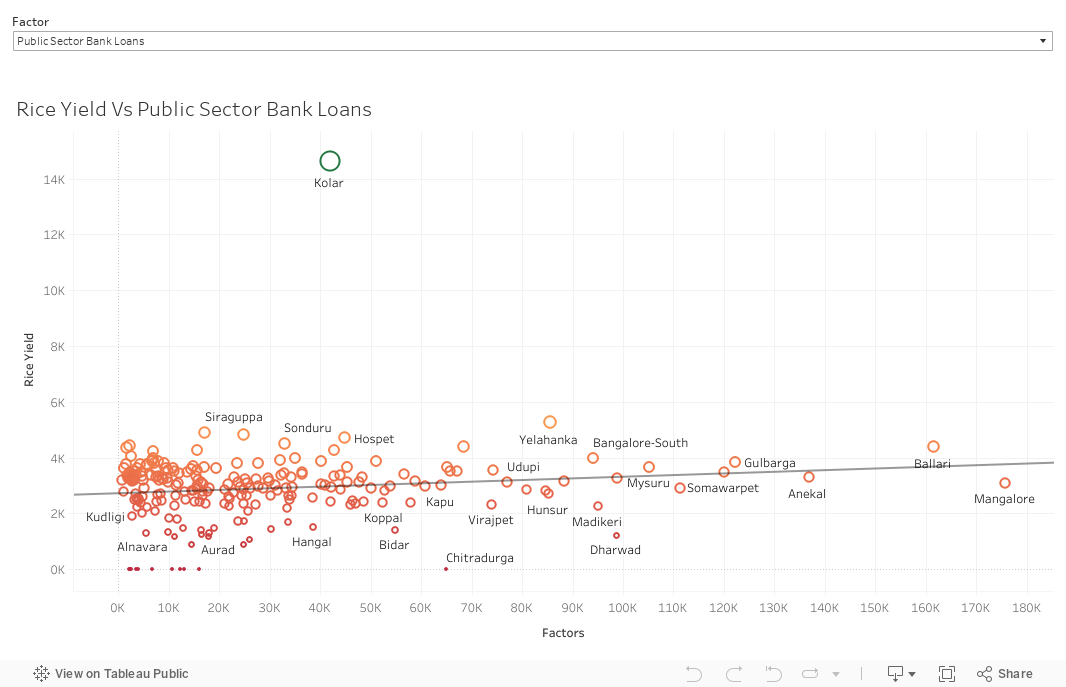
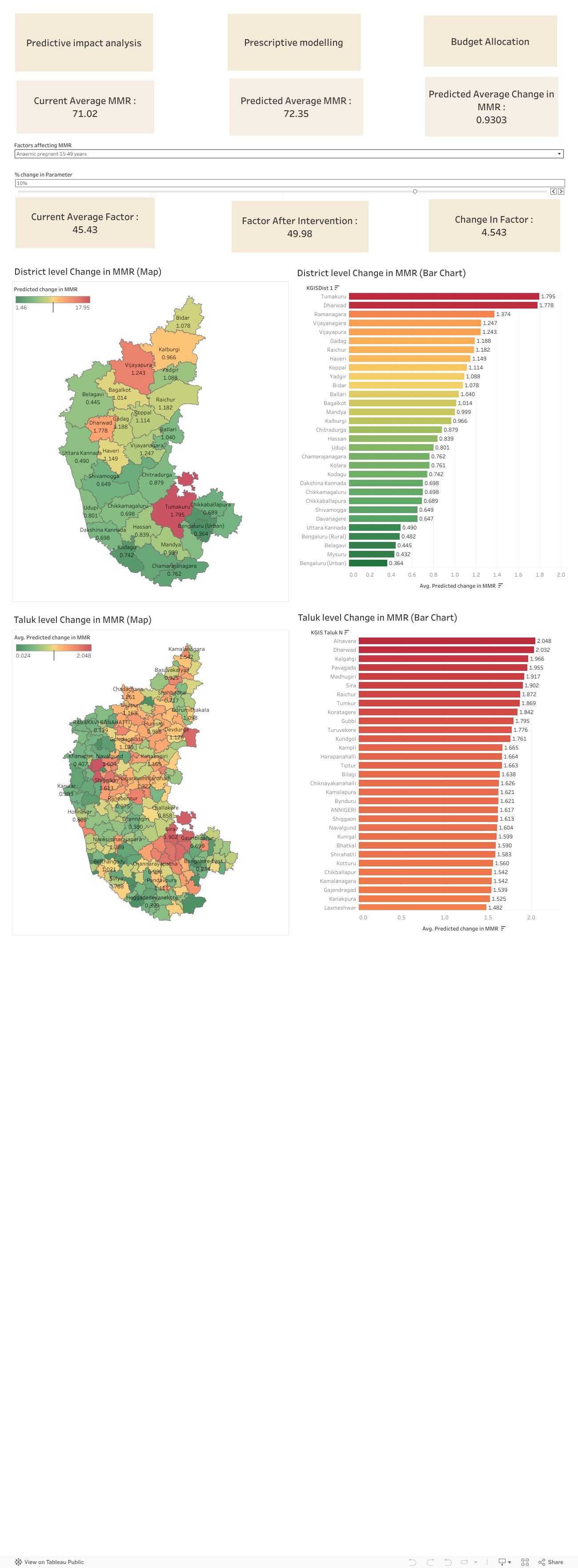
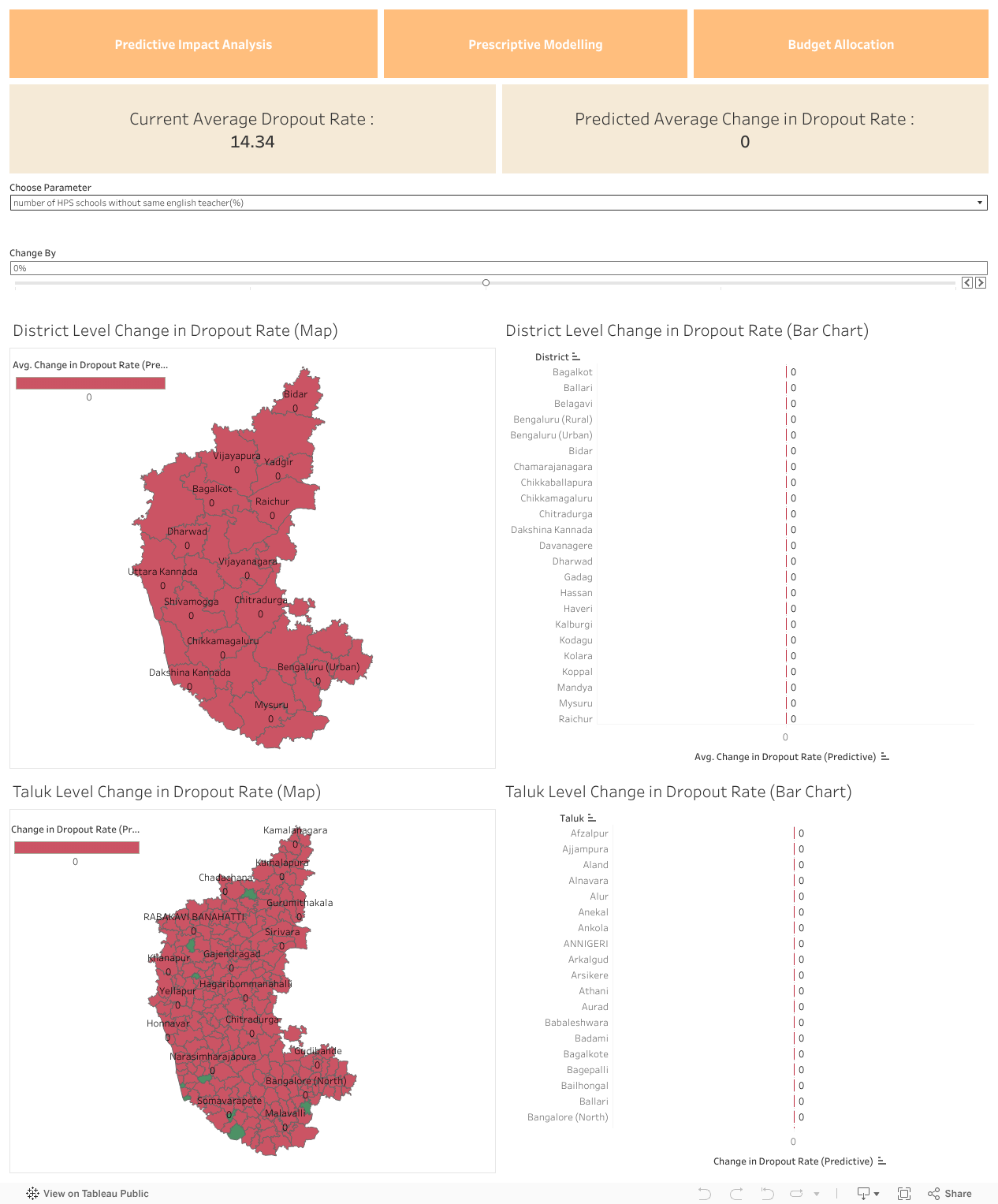
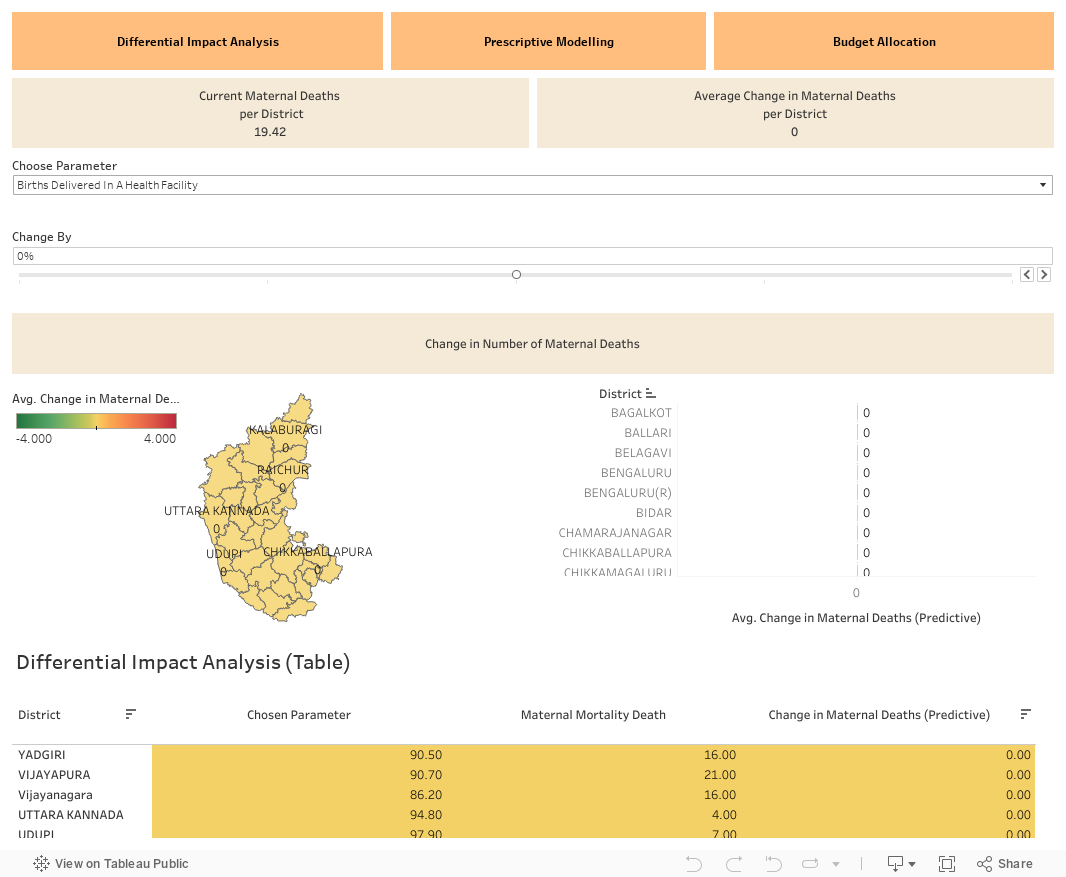
In the Predictive Impact Analysis dashboard, we can see the impact of different factors on Student Drop-out Rate (SDR). We can intervene on a factor by selecting it from the dropdown menu and changing it by any amount (eg: +10% , -10%, etc) and we can see the corresponding changes in the rate at the district level.
In the Prescriptive modelling dashboard, we can set the target SDR and the model outputs the prescribed values of different factors to achieve the specified target SDR. We can also see the corresponding change in SDR at the district level by adopting these prescribed values of the factor. We can also see sensitivities of different factors which talks about the importance of the factor and it ranges from 0 to 1. If a domain expert deems a specific factor as unimportant, they can assign a sensitivity value of 0. For factors considered partially important, a sensitivity value of 0.5 can be assigned. If the expert believes the factor unquestionably plays a role, they have the option to set its sensitivity to 1.
In the prescriptive modelling dashboard itself, there is a box displaying the state stability score after an intervention. There is also a scatter plot showing the relation between impact and stability with districts represented as points.
Finally, the dashboard includes a feature for budget allocation. Positioned at the top is a pie chart derived from slopes obtained from multiple linear regression. The methodology systematically distributes the budget to address the requirements of various districts. Here, as well, we can see the sensitivities of the factors. If the policy maker/domain expert thinks that a particular factor plays no role, he can set its sensitivity value to 0 and the budget allocation model will automatically get re-adjusted.