Overview:
Organizational learning is fast becoming an integral element of the daily operations of organizations given the pace of change in technology and market dynamics. Organizational learning is the process of creating, retaining, and transferring knowledge within an organization. An organization improves over time as it gains experience. From this experience, it is able to create knowledge. This knowledge is broad, covering any topic that could better an organization. Organisational learning is an essential element for the survival of any organisation in this fast paced technological and business landscape.
A concept of “learning organizations” has been a focus of enormous research and managerial interest since the early 1990s. Peter Senge, identifies five key disciplines for organizational learning:
- Systems Thinking
- Shared Vision
- Mental Models
- Team Learning
- Personal Mastery
While the concept of learning organizations elicited enormous interest in its early years, the above principles of learning organizations were found to be very challenging to manage, in an environment of fast changes and churn in the workplace.
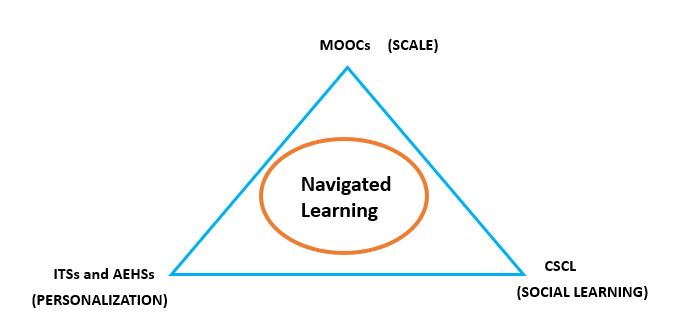
In recent times, a new paradigm called precision learning is gaining a lot of research attention. Precision learning entails the use of “Big Data” techniques to identify expertise and knowledge gaps in a given community or organization, and mediate between them. The result is a continuous, on-going process of learning catering to a population of diverse interests, skills and learning goals.
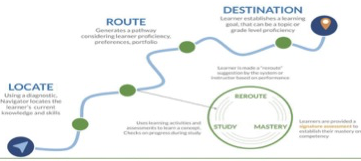
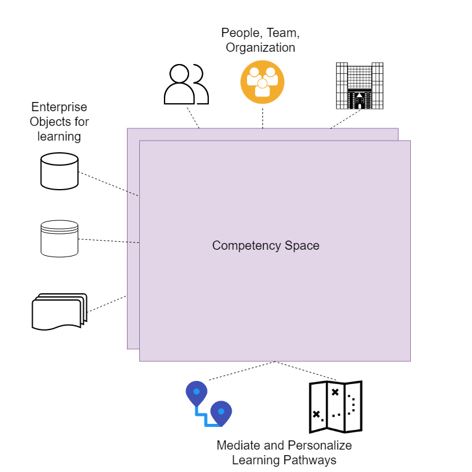
Navigated Learning is a precision learning model being developed at the Web Science lab at IIIT Bangalore. Navigated learning implements precision learning, by computing a variety of semantic embeddings. This project explores Navigated Learning models for enterprise settings.
Expected Social Impact:
Navigated learning is part of the research focus called “Digital Empowerment” being pursued by the Web Science lab. The underlying social challenge being addressed is the need for informal and continuous upskilling required for overall social empowerment. Current models of technology enabled learning have not gained enough engagement and traction from users to pursue their upskilling activities in a sustained manner. One of the reasons we believe for this, is the dearth of context, relevance and social support during the learning process. Navigated learning is expected to cater to this need, and we hope that it becomes as popular as, and an empowering alternative to streaming video and gaming apps.
Since this is under applied research in cognitive computing “Precision Learning for Enterprise portal” will be delivered in which the concept of Navigated Learning is applied.
This project is sponsored by Mphasis under the Mphasis Center of Excellence for Cognitive Computing.
Team Members:
Dr Aparna Lalingkar, Postdoctorate Research Fellow
Mr Prakhar Mishra, MS Research Scholar
Mr Shyam Kumar VN, MS Research Scholar
Current Members:
Jagatdeep Pattanaik, MTech Student
Puneeth Sarma, IMTech Student
Rohit Katlaa, IMTech Student