
Understanding how learner interactions shape collective learning outcomes
Learning is often viewed as an individual process, where success depends primarily on the learner and the content they consume. However, decades of research suggest that learning is also deeply social. Learners influence one another through discussion, collaboration, feedback, and shared experiences.
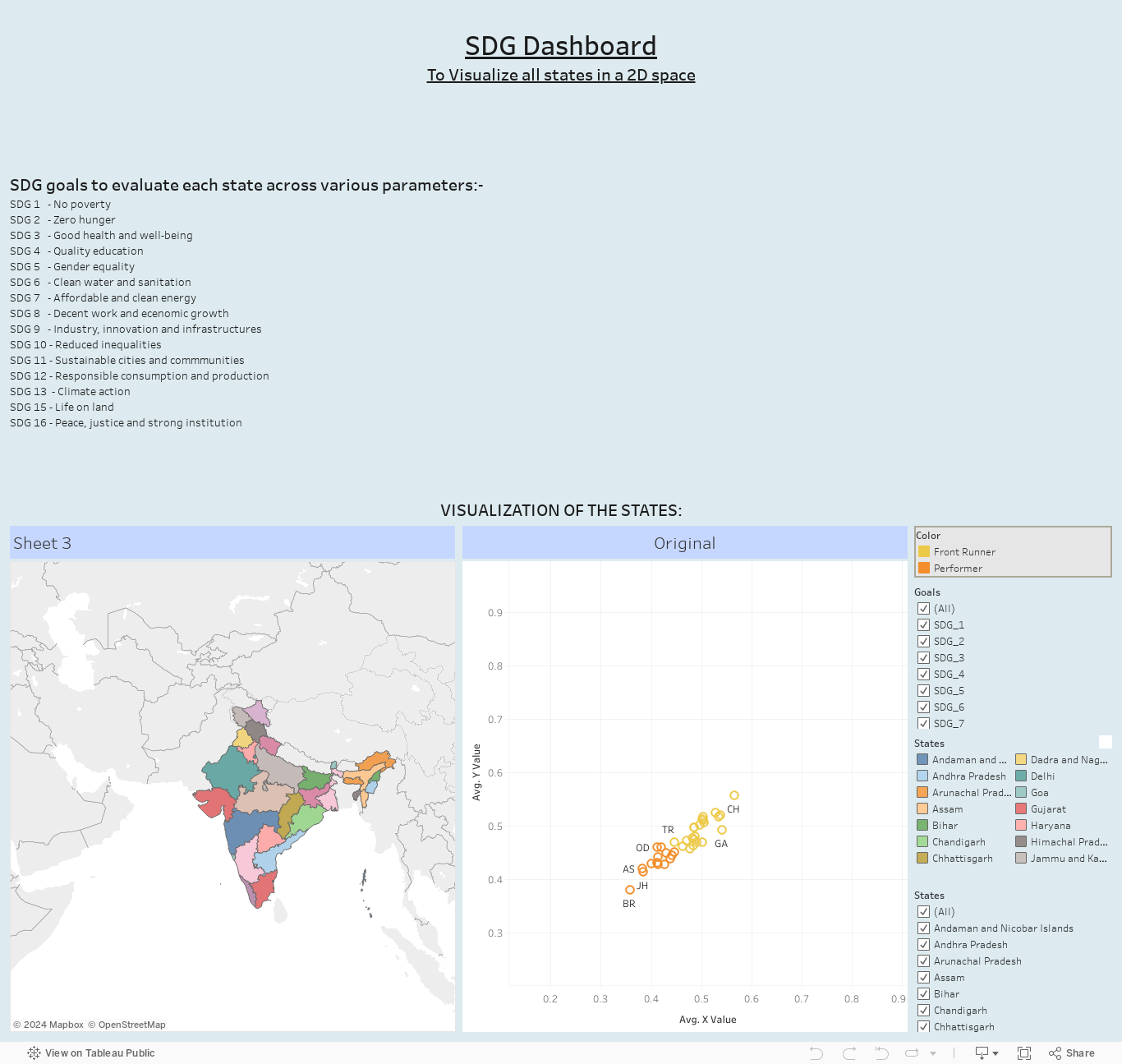
This project explores how interactions between learners shape collective learning outcomes. By combining ideas from learning sciences and network science, it investigates how learning communities evolve and how patterns of coordination emerge through repeated interaction.
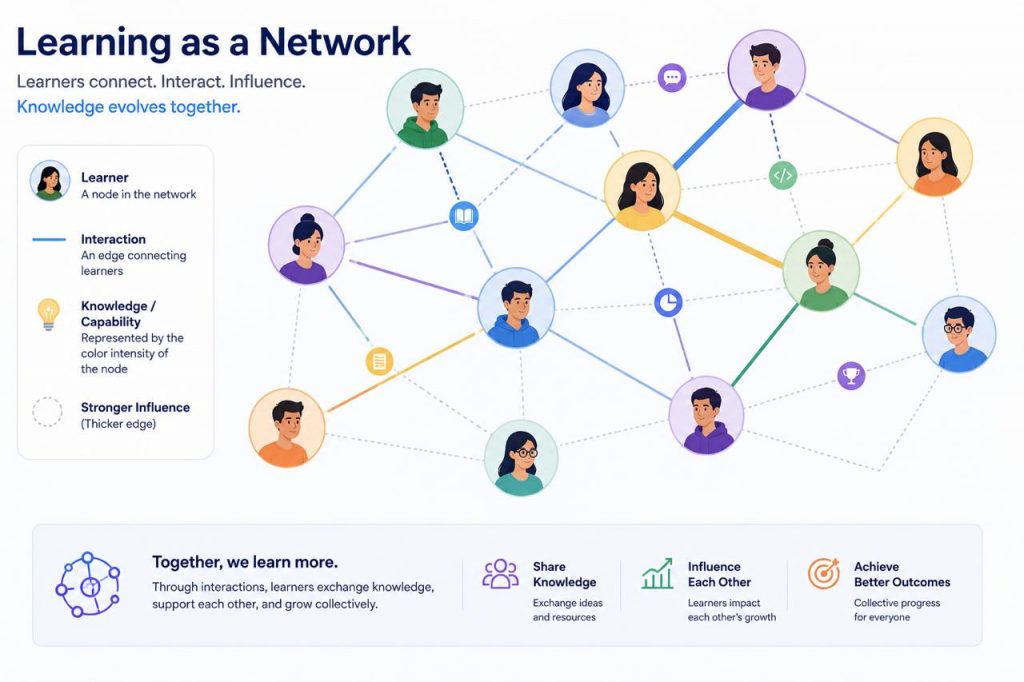
Learning as a Network
The project models a learning community as a network, where learners are represented as nodes and interactions between learners form the connections.
This perspective shifts the focus from individual learning trajectories to the behavior of the community as a whole. It allows us to study how information flows, how learners influence one another, and how collective outcomes emerge over time.
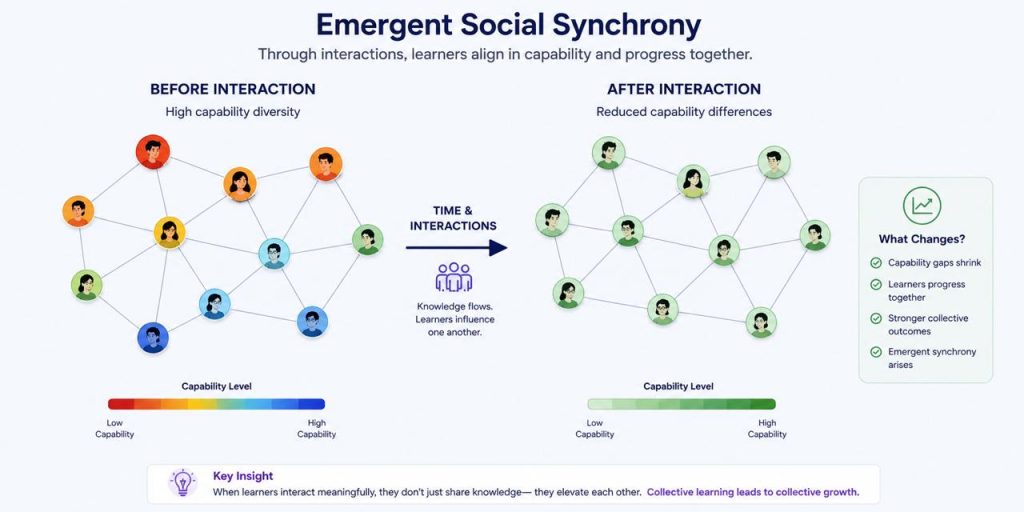
Social Synchrony
One of the central ideas explored in this work is social synchrony—the tendency of learners to gradually align in capability and progress through interaction.
As learners exchange knowledge and experiences, differences within the community can reduce, resulting in more coordinated learning behavior and stronger collective outcomes.
The concept draws inspiration from foundational work in social learning, sociocultural learning, communities of practice, and networked learning.
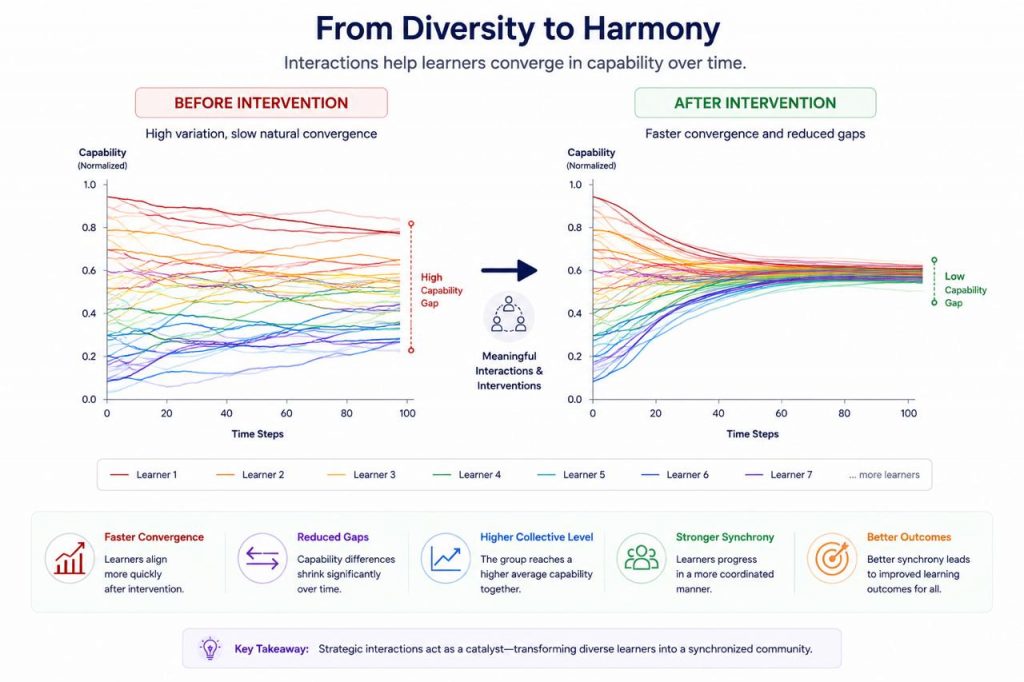
Key Findings
The study demonstrates that learner interactions play an important role in shaping collective outcomes. Across simulated learning communities, repeated interaction was associated with the emergence of synchrony and reduced capability disparities among learners.
These findings suggest that understanding learner-to-learner relationships may be as important as understanding learner-to-content relationships when designing future learning systems.
Research Outputs
Publication
Modeling Outcomes-led Learner Behavior and Emergent Social Synchrony Ashashree Sarma, Sushree Behera, Srinath Srinivasa, and Prasad Ram. Proceedings of the Twelfth ACM Conference on Learning @ Scale (L@S 2025), Palermo, Italy. DOI: 10.1145/3698205.3733959
https://dl.acm.org/doi/abs/10.1145/3698205.3733959
Poster Presentations
- RISE 2025
- L@S & EDM 2025
- WebSciX 2025
Media Coverage
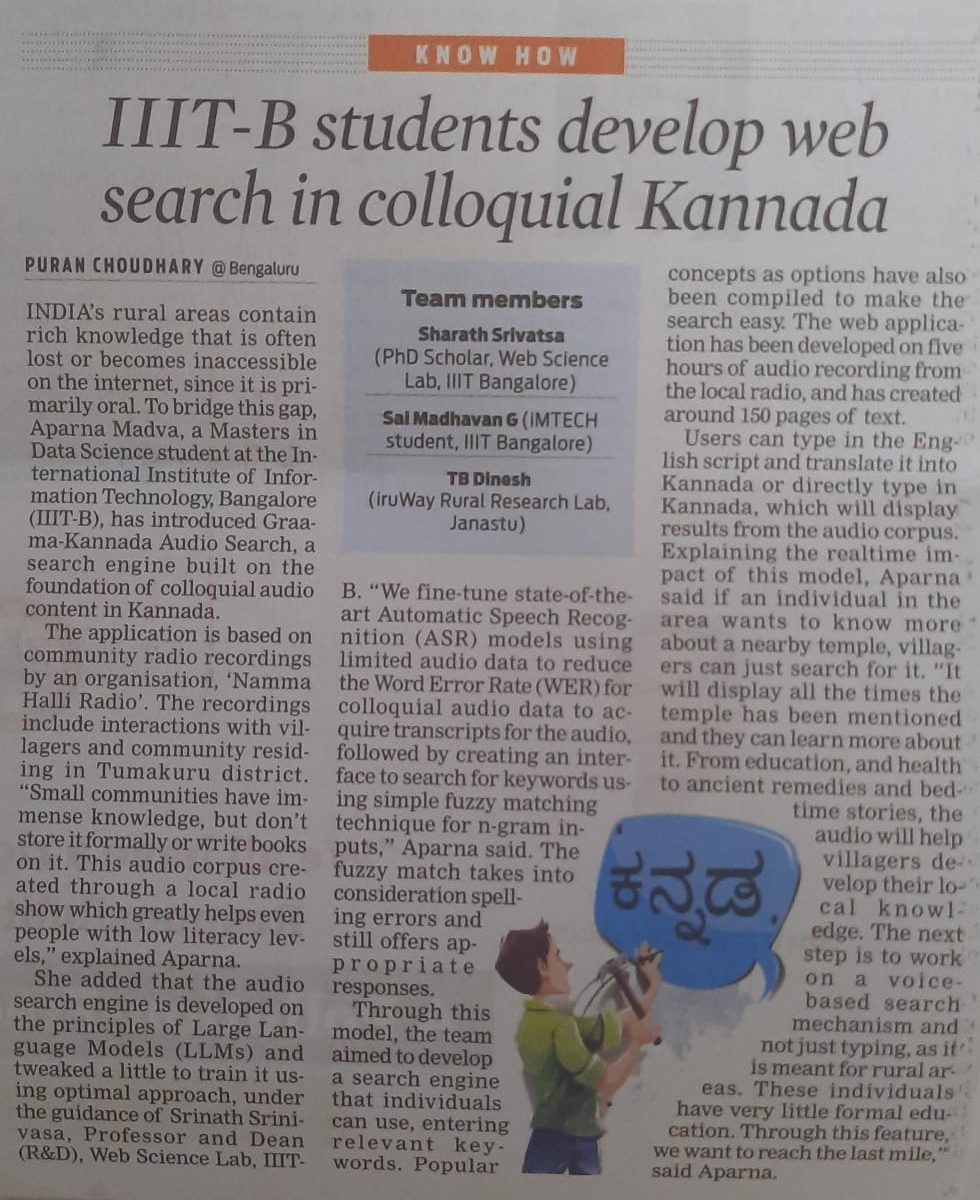
Google Maps for Learning: IIIT-B Researchers Develop AI Navigator for Personalised STEM Learning https://www.thehindu.com/news/national/karnataka/google-maps-for-learning-iiit-b-researchers-develop-ai-navigator-for-personalised-stem-learning/article70089077.ece
Featured in The Hindu.
Foundations
This work draws inspiration from:
- Albert Bandura’s Social Learning Theory
- Lev Vygotsky’s Sociocultural Theory
- Etienne Wenger’s Communities of Practice
- George Siemens’ Connectivism
- Complex Systems and Network Science
People
Project Lead
Ashashree Sarma
Research Scholar, IIIT Bangalore
Research Profile: https://wsl.iiitb.ac.in/ashashree-sarma/
LinkedIn: https://www.linkedin.com/in/ashashree17321/
Supervisors
Prof. Srinath Srinivasa
Professor, IIIT Bangalore
Profile: https://wsl.iiitb.ac.in/srinath-srinivasa/
Prof. Sushree Sangeeta Behera
Faculty, IIIT Bangalore
Profile: https://wsl.iiitb.ac.in/sushree-behera/