Unlocking Mobility to Improve Urban Life in Bengaluru
Bengaluru faces one of the most severe traffic congestion challenges in India. Rapid population growth, economic expansion and increasing vehicle ownership have placed immense pressure on the city’s transport infrastructure. Daily gridlock has become a defining feature of urban life, leading to longer commute times, higher air pollution, reduced productivity, and a declining quality of urban life.

Recognizing that conventional solutions such as road widening and flyovers cannot resolve these systemic challenges, Bengaluru requires a more integrated, forward-looking approach to mobility one that goes beyond city limits and addresses regional travel patterns.
Rethinking Mobility for a Growing Megaregion
To respond to this challenge, we are developing a transformative initiative:
Project Title: Multi-Modal Mobility Solutions for Megaregions around Bengaluru
Once known as the Garden City and now India’s technology capital, Bengaluru has grown rapidly over the past five decades. While this growth has brought innovation, talent, and economic opportunity, it has also resulted in stressed infrastructure, fragmented transit systems, congestion, climate pressures, and limited freight capacity. Addressing these challenges requires moving beyond the scale of a single city.
Across Karnataka, population and economic activity are spreading unevenly, with new growth centers emerging beyond Bengaluru’s urban core. In this context, megaregional planning and multi-modal mobility offer a new paradigm for sustainable development.
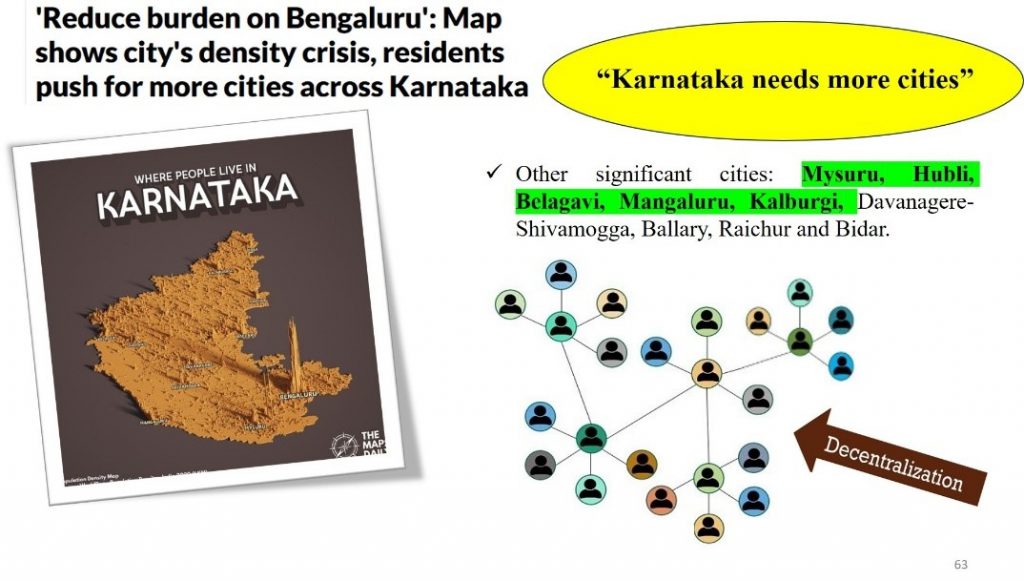
What Is a Megaregion?
A megaregion is a large, networked geographic area that extends beyond individual cities and administrative boundaries. It is formed by multiple interconnected growth centers that are economically and functionally interdependent, collectively driving regional and national development.
The Bengaluru megaregion extends well beyond the city’s current periphery, encompassing emerging centers, each with distinct strengths and development potential. As growth increasingly clusters across these locations, mobility planning must evolve to treat the region as a single, integrated system.

Data-Driven Planning for Integrated Connectivity
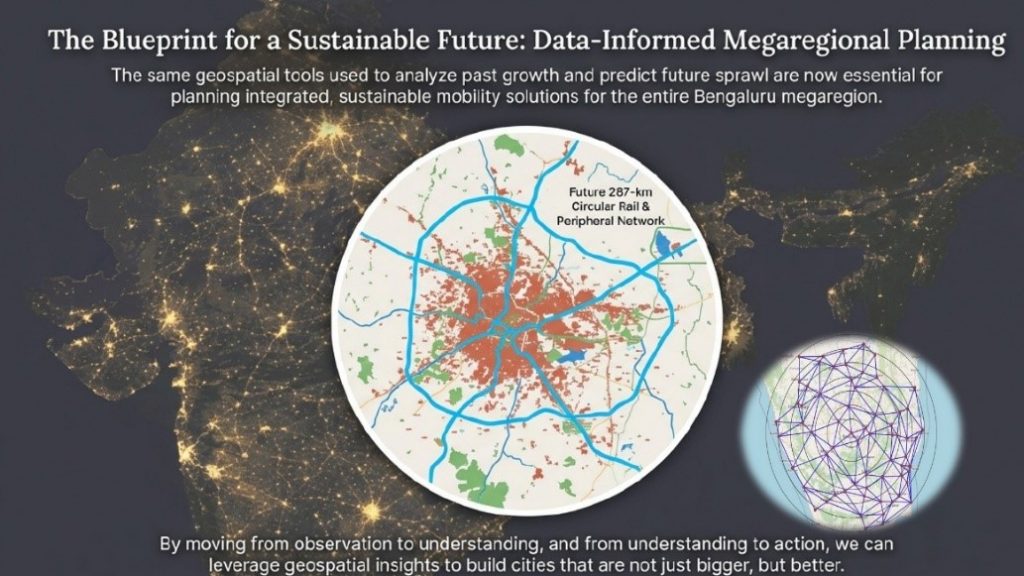
Understanding travel demand, growth corridors, and inter-city linkages enables smarter, more resilient mobility planning. Improved regional connectivity through suburban rail, metro systems, highways, regional rapid transit systems, high-speed rail proposals (such as the Chennai–Mysuru corridor), and shared mobility can activate new economic nodes, strengthen rural–urban integration, and distribute opportunities more evenly across the state.
This project leverages satellite imagery, geospatial analytics, night-time lights data, transport network modeling, and real-time mobility insights to delineate megaregional boundaries, anticipate future growth patterns, identify strategic mobility corridors, and propose integrated, multi-modal transport solutions.

By enabling efficient, low-carbon movement of people and goods, a balanced network of cities can reduce migration pressures on Bengaluru, ease congestion, and support more livable, resilient communities across megaregion.
Aligning with National and Regional Vision
This initiative aligns closely with Viksit Bharat 2047, supporting sustainable, inclusive, and intelligent urban and regional development. Megaregional planning opens new pathways for investment, industry, innovation, and equitable access to opportunity.
Stronger connectivity between Bengaluru and small and medium towns can foster diversified economic growth, reduce pressure on the capital, and enhance quality of life across the region. The study of megaregional mobility is more than a research effort, it is a long-term vision for balanced, sustainable growth.
The study of megaregional mobility is enabled by Bengaluru Science and technology (BeST) Cluster (https://www.bestkc.in/), an initiative by the Office of the Principal Scientific Adviser to the government of India.